
How to Predict the Success of Startups using ML
Leverage data science, machine learning, and business principles to predict the success of startups based on common characteristics

Written by Shiyan Boxer

Overview
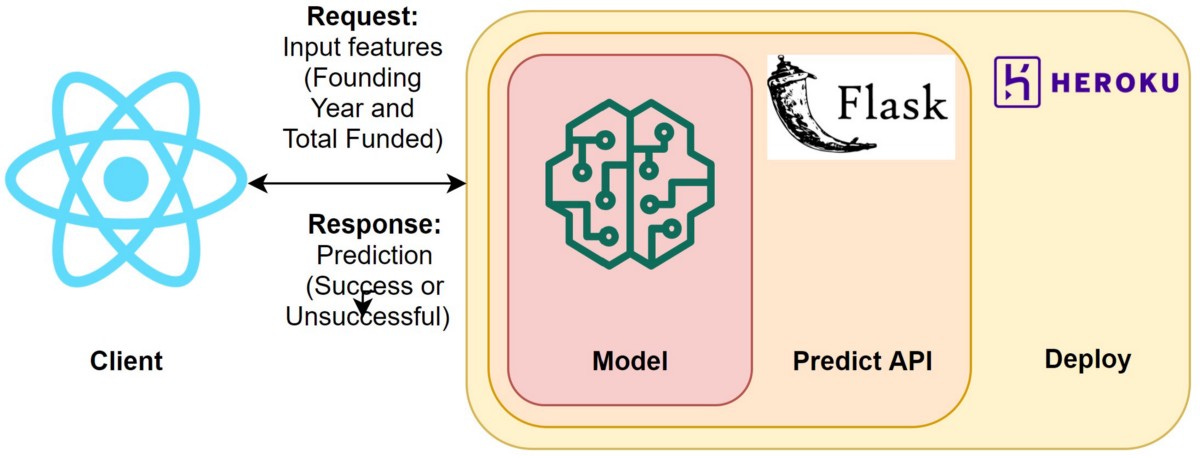
This web application leverages data science, machine learning, and business principles to predict the success of startups based on common characteristics. The goals throughout the development process are to ensure reliability, scalability, and ease of use. The program is an end to end solution consisting of four parts:
Clean cleans dataset before building the model
Model predicts success
API allows requests to the model
Frontend allows user to inputs criteria
Demo
Problem Definition
Traditionally, venture capital is considered more of an art than a science. Venture capitalists meet with founders, perform due diligence, and try to make the most informed investment decision; however, due to the nature of early-stage companies, financial and traction metrics are often scarce.
Objectives
With the influx and access to data in recent decades, venture capitalists have turned to machine learning and artificial intelligence to help guide them in their investment decisions and explore market trends. Typically models are built, not with the intention to replace VCs but rather to enable them to quantify opportunities and avoid bias as much as possible.
This web application leverages data science, machine learning, and business principles to predict the success of startups based on common characteristics. The goal is to ensure reliability, scalability, and ease of use. These goals are met by the following design choices:
Reliability: VCs are given accurate predictions. This is achieved by using an appropriate model, testing, and tuning until it reaches above 90% accuracy.
Scalability: The technologies chosen for the web application enable the web app to be altered and scalable.
Ease of Use: The user interface is intuitive to the user, eliminating any confusion.
Technologies
React to build the frontend
Python 3.7 in Jupyter Notebook to build the model and clean
Flask to build the API
MongoDB to build the database
Steps
Clean
The first step was to clean the dataset so it could be used by the model. This code can be found in the Clean folder of the repository. I made the following changes:
Create a new excel sheet that will have changes “after.xlsx”
Remove companies with NA from the dataset
Make a new column for company “success” (0 = “operating or “acquired” and 1 = “closed”)
import pandas as pd # Open the xlsx file and store the DataFrame in variable "df" df = pd.read_excel("C://Users//shiya//Documents//FF//Startup-Success-Predictor-v2//after.xlsx")# Remove any NA valuesdf = df.dropna(axis=0, how='any') # drop rows (axis = 0), if (any) NA appear # Create new column for success, 1 = “operating or “acquired” and 0 = “closed”df['success'] = df['status'].apply(lambda x: 0 if 'closed' in x.lower() else 1)Model
The model was built by doing the following:
Choose relevant columns
Get dummy data
Split training and testing data
Multiple linear regression
Test accuracy
Pickle model
import pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import accuracy_scoreimport pickle# Choose relevant columns (funding_total_usd, success, country_code, founded_year) and assign the filtered dataset to a variable called "df_model"df_model = df[['success','funding_total_usd','founded_year']]# Get dummy data on df_model using the get_dummies()df_dummie = pd.get_dummies(df_model)# Create x and y variablesX = df_dummie.drop('success', axis =1) # axis = 1 means drop columny = df_dummie.success.values# Create train and test setsX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)## Linear Regressionmodel = LinearRegression()# Fit linear model fit(X, y[, sample_weight])model.fit(X_train, y_train)# Test accuracy (0.9437570303712036)accuracy_score(y_test, np.around(model.predict(X_test),0))# Pickle the model so it can be loaded in the Flask APIpickl = {'model': model.fit(X_train, y_train)}pickle.dump( pickl, open( 'model_file' + ".p", "wb" ) )file_name = "model_file.p"with open(file_name, 'rb') as pickled: data = pickle.load(pickled) model = data['model']API
In this step, I built a flask API endpoint that was hosted on a local webserver.
Pickle the model. This converts the object into a byte stream which can be stored, transferred, and converted back to the original model at a later time. Pickles are one of the ways python lets you save just about any object out of the box.
Build Flask API. This allows other users and our frontend to send requests and receive a response (prediction).
import flaskfrom flask import Flask, jsonify, requestimport pickleimport jsonimport sklearn as sklearnimport numpy as npfrom flask_cors import CORS@app.route('/predict', methods=['POST'])def predict(): """ Predict the success of a company from the user's input Return: "response" which is a value either 1 or 0. """ model = load_models() # Get an instance of the model calling the load_models() data = json.loads(request.data) # Load the request from the user and store in the variable "data"total_funding = float(data['total_funding']) # Break down each input into seprate variables founded_year = float(data['founded_year'])X_test = np.array([total_funding, founded_year]) # Create a X_test variable of the user's input prediction = model.predict(X_test.reshape(1, -1)) # Use the the X_test to to predict the success using the predict() response = json.dumps({'response': np.around(prediction[0], 0)}) # Dump the result to be sent back to the frontendreturn responseDeploy API
I deployed the API to Heroku.
Create an app “create startup-success-predictor-api”
Push the app to Heroku “git push Heroku master”
Get a link to send API requests https://startup-success-predictor-api.herokuapp.com/
Frontend
I created a simple website using React to interact with the API.
Make a request to API curl -X GET https://flask-ml-api-123.herokuapp.com/predict
Connect API to frontend forms component
Deploy the website to Netlify
Demo
Startup Success Predictor
Edit descriptionstartup-success-predictor.netlify.app
GitHub Repository
shiyanboxer/Startup-Success-Predictor-v2
npm install pip install -r requirements.txt This web application leverages data science, machine learning, and business…github.com